How Sample Size Affects Supplement Study Results

Does a supplement's study sample size matter? Absolutely. Smaller studies often exaggerate benefits or miss real risks, while larger ones provide more precise, reliable results. Here's the key takeaway: the number of participants in a study directly impacts how much you can trust its claims.
- Small Studies: Prone to errors like false positives (overstated benefits) or false negatives (missed effects). They often fail to detect rare side effects or provide consistent results.
- Large Studies: Offer clearer insights but can sometimes highlight trivial differences that don't matter in daily life.
- What to Look For: Studies with at least 50–100 participants, proper power calculations (80–90%), and diverse participant groups for broader applicability.
Tools like SlipsHQ simplify this process. By scanning a supplement's barcode, you can see if its claims are backed by well-designed studies with adequate sample sizes. This helps you avoid wasting money on unproven products and focus on what works.
Basic Study Concepts Related to Sample Size
What Sample Size Means and Why It Matters
Sample size refers to the number of participants involved in a study - whether that’s 20 or 2,000. In supplement research, the size of the sample plays a major role in determining how reliable the results are. Smaller samples are more prone to errors, such as missing real effects or producing false positives. For example, if a study includes only 15 participants in each group, random fluctuations in such a small sample can distort the results. This can weaken the study’s ability to detect real changes and make it harder to apply the findings to a wider population.
The goal is to have a sample size large enough to identify meaningful effects without wasting resources. For instance, a well-designed trial comparing a heart health supplement to a placebo might need 116 participants in the treatment group and 58 in the control group to detect a 5% improvement in LDL cholesterol with 90% power, factoring in a 10% dropout rate. This balance ensures the study is both efficient and effective at capturing useful data.
Research Terms Explained
When reviewing supplement studies, you’ll often come across several important statistical concepts:
- Statistical power measures a study’s ability to detect a real effect. Researchers typically aim for 80–90% power. If the effect size is very large - like a 2.5 standard deviation improvement - a small sample of just 8 participants might suffice. However, smaller and more realistic effects require much larger samples to achieve similar power.
- Effect size describes the strength of the change caused by a supplement, independent of the sample size. For instance, a psychology replication project found that small initial studies reported effect sizes around r = 0.40. However, when tested with larger samples, the effect sizes dropped to r = 0.20 - about half the original estimate.
- Confidence intervals (CIs) give a range where the true effect is likely to fall. A 95% CI means that if the study were repeated 100 times, 95 of those intervals would include the real effect. Smaller samples produce wider intervals, reflecting greater uncertainty, while larger samples yield narrower, more precise intervals.
- P-values assess how well the data align with the idea that the supplement has no effect (the null hypothesis). A p-value below 0.05 is often considered “significant,” but its meaning can vary depending on sample size. Small studies might miss true effects due to variability, while very large studies can highlight statistically significant differences that may not be clinically meaningful.
Common Study Designs in Supplement Research
Studies on supplements often rely on a few standard research designs, each with unique sample size needs:
- Randomized controlled trials (RCTs) are considered the gold standard. In parallel-group RCTs, participants are assigned to either the supplement or a placebo group. To reliably detect modest effects, at least 50–60 participants are typically recommended. Smaller groups increase the chance of overlooking real benefits or being misled by random variations.
- Crossover studies have participants act as their own control, receiving both the supplement and placebo at separate times. This design reduces variability and often requires fewer participants. However, it must be carefully planned to address potential carryover effects between treatment periods.
- Observational studies, like cohort or case-control designs, track outcomes in real-world settings without assigning treatments. These studies often involve more diverse populations, which can help generalize findings. However, they provide weaker evidence of causation compared to RCTs. Proper sample size calculations - including expected effect size, target power, significance level, and dropout rates - are critical for evaluating the quality of these studies.
Grasping these concepts provides a solid foundation for understanding how sample size shapes the reliability of research findings.
How Sample Size Affects Study Reliability
How Sample Size, Power, and Effect Size Work Together
The interplay between sample size, statistical power, and effect size is key to determining whether a supplement study can reliably detect real benefits. Statistical power refers to the likelihood of identifying a true effect if one exists - most researchers aim for power levels between 80% and 90%. If the sample size is fixed, power decreases as the effect size gets smaller. For example, a very strong effect (around 2.5 standard deviations) might only need 8 participants per group to detect, but the smaller, more modest improvements often seen with supplements typically require dozens or even hundreds of participants to achieve sufficient power.
Larger sample sizes help reduce random error and produce narrower confidence intervals, bringing estimated effects closer to the true population value. This precision is critical in distinguishing a supplement that genuinely works from one that shows positive results purely by chance in a small group. This dynamic highlights the unique challenges posed by small sample sizes.
Problems with Small Sample Sizes
Balanced sample sizes are essential for reliable findings. Small studies carry a greater risk of both type I errors (false positives) and type II errors (false negatives), which can undermine the reliability of results.
Additionally, effect sizes reported in small studies are often exaggerated. Research shows that smaller studies tend to overestimate benefits, a problem that larger, more robust trials help correct. Small studies also exhibit higher variability and inconsistency, making it harder to trust a single small trial's findings on a supplement ingredient. For consumers, this often translates into bold claims based on tiny pilot studies with wide confidence intervals, which frequently fail to hold up in subsequent research.
When Large Sample Sizes Create Problems
On the flip side, very large sample sizes can detect tiny differences that are statistically significant but have little practical importance. For instance, a 0.5 mg/dL reduction in LDL cholesterol might achieve a p-value below 0.05 in a study with thousands of participants, but such a small change wouldn't impact a doctor's treatment plan or significantly alter a person's cardiovascular risk. As sample sizes increase, even minuscule effect sizes can yield extremely low p-values, creating the illusion of importance when the result may not matter for real-world outcomes like symptoms or quality of life.
Overly large trials can also raise ethical concerns and waste resources by identifying trivial differences with no meaningful clinical impact. Striking the right balance in sample size is essential. The goal is to design studies with the smallest sample size that still provides adequate power and precision, minimizing participant burden while maximizing scientific value.
What to Look for When Evaluating Supplement Studies
Warning Signs in Study Sample Sizes
When diving into supplement research, certain red flags should make you pause. One of the biggest concerns? Tiny sample sizes - usually fewer than 20 to 30 participants in each group. Studies with such small numbers are more prone to producing misleading results, either falsely positive or negative. For instance, if a study boasts dramatic outcomes but only tested 15 people on the supplement and 15 on a placebo, it's wise to approach those claims with caution.
Another issue to watch for is the lack of power calculations. If researchers don’t explain how they decided on the number of participants, it often signals poor planning. Let’s say a study compares a new supplement to an established treatment. If the researchers assume both are equally effective but fail to recruit at least 60 participants (30 per group), they risk drawing unreliable conclusions due to insufficient statistical power. Small, unreplicated pilot studies only add to this uncertainty.
It’s also important to understand that certain study designs demand specific minimum participant numbers. For example, studies with fewer than 60 participants overall often lack the statistical weight needed to apply their findings to a larger population.
Spotting these issues is crucial for filtering out weaker studies. Once you’ve identified the red flags, it’s time to focus on what makes a study reliable.
Indicators of Quality Evidence
Strong supplement studies tend to share key characteristics. At the top of the list are well-powered randomized controlled trials (RCTs). These studies calculate sample sizes in advance, factoring in potential dropouts, and aim for statistical power levels of 80% to 90% at a 5% significance threshold. Look for statements like this: “116 participants in the treatment group and 58 in the control group were included to achieve 90% power, assuming a 10% standard deviation and a 10% dropout rate”.
Another hallmark of quality research is pre-registered outcomes and replication across independent studies. These features help ensure the results aren’t random flukes. Prospective cohort studies are generally more reliable than retrospective or cross-sectional ones, while repeated RCTs provide unbiased effect size estimates through cross-validation.
Additionally, good studies include effect sizes that are independent of sample size, such as Cohen’s d, number needed to treat (NNT), Pearson r, or differences in success rates. They also feature detailed statistical plans that explain how the data was analyzed. Together, proper sample sizes, power, and replication build a study’s credibility.
Using Tables to Compare Study Quality
To make evaluating studies easier, a comparison table can help you quickly identify which ones meet quality benchmarks. A well-structured table might include columns for sample size, power calculations, effect sizes, replication status, study design, risk level, and overall evaluation:
| Study | Sample Size | Power | Effect Size | Design | Replication | Risk Level | Evaluation |
|---|---|---|---|---|---|---|---|
| A | 20/group | None | d=0.8 | Pilot | No | High (false positives) | Skeptical |
| B | 100/group | 90% | d=0.2 (NNT=10) | RCT | Yes | Low | Trustworthy |
This kind of table simplifies the process of assessing study quality. It highlights critical factors like whether the sample size is sufficient (usually over 50 to 100 participants per group, accounting for dropouts), whether power calculations were done, if the effect sizes are meaningful, and whether the results have been independently replicated. These are the key elements to consider when evaluating the validity of supplement claims.
What Sample Size Means for Supplement Users

Small vs Large Supplement Studies: Sample Size Comparison Guide
How Sample Size Affects Confidence in Results
The number of participants in a study directly impacts how reliable its results are. Studies with small sample sizes often provide early insights but usually need larger trials to confirm their findings. If you're basing decisions on a study with only a handful of participants, it’s wise to look for follow-up research or meta-analyses that can provide a broader perspective.
When studies involve larger groups, their results tend to be clearer because they produce narrower confidence intervals. This clarity helps reveal a supplement's actual effects. On the other hand, smaller studies often leave more room for uncertainty. For instance, a small trial might report a 5 mm Hg drop in blood pressure, but larger studies could show the effect is much smaller - or even nonexistent.
Large sample sizes are also essential for identifying rare side effects. For example, detecting adverse events that occur in about 1 in 500 or 1 in 1,000 users requires trials with hundreds or even thousands of participants. Small studies, by contrast, are unlikely to uncover anything beyond frequent or obvious side effects. They may highlight short-term benefits but often fail to provide insights into rare or long-term safety concerns.
Beyond the numbers, the diversity of participants plays a big role in determining how applicable the findings are to your own health situation.
Participant Diversity and Applying Results
Even a study with a large number of participants can fall short if its sample lacks variety. Imagine a trial that only includes healthy men aged 18–35. The results from such a study might not apply to older adults, women, or people with chronic health conditions. To understand how a study’s findings might relate to your own health, it’s crucial to check whether the participants are similar to you in terms of age, sex, health status, and ethnicity. Without this diversity, even a large trial might not provide the guidance you need for evaluating your own risk and benefits.
Smaller, targeted studies often recruit relatively healthy individuals under controlled conditions. While this approach can strengthen the study’s internal validity, it may limit how well the results apply to the broader, more varied U.S. population. In contrast, larger trials and well-designed observational studies often include a wider range of participants, making their findings more broadly applicable.
Small vs. Large Trials: Comparison
Understanding the differences between small, preliminary trials and large, confirmatory ones can help you better evaluate supplement claims. Preliminary trials are quicker and less expensive, making them useful for testing new ideas and generating hypotheses. However, their smaller sample sizes often mean less reliable results, with unstable effect estimates and limited safety data. Larger trials, while more time-consuming and costly, tend to provide stronger evidence. They offer more precise estimates of benefits, better detection of rare side effects, and more robust data to guide health decisions.
For example, a modest and consistent benefit observed in a large, well-conducted trial is often more trustworthy than a dramatic result from a small study. When evaluating supplement research, it’s important to consider the total body of evidence. Studies with larger sample sizes and tighter confidence intervals should carry more weight, even if their findings seem less dramatic than those from smaller trials.
To make this comparison easier, here’s a breakdown of the strengths and weaknesses of small versus large trials:
| Aspect | Small / Pilot Supplement Trials | Large / Confirmatory Supplement Trials |
|---|---|---|
| Purpose | Explore initial ideas and generate hypotheses | Confirm effectiveness, measure benefits, and assess safety |
| Sample Size & Power | Typically involves dozens of participants; often underpowered and prone to false positives or negatives | Includes hundreds or more participants; designed to achieve at least 80% power with clear outcomes |
| Effect Size Estimates | Often imprecise with wide confidence intervals; effects may be exaggerated and hard to replicate | Generally more accurate with narrower confidence intervals |
| Safety Data | Limited ability to detect rare or moderate side effects; shorter follow-up periods | Better at identifying common and some rare side effects, especially with longer follow-ups |
| Generalizability | Often based on narrow, homogeneous samples, limiting how broadly results apply | More likely to include diverse participants, improving applicability if well-designed |
| Usefulness for Consumers | Findings are suggestive but should not drive health decisions alone | Provides stronger, more reliable evidence, especially when results are replicated |
How SlipsHQ Helps You Evaluate Study Quality
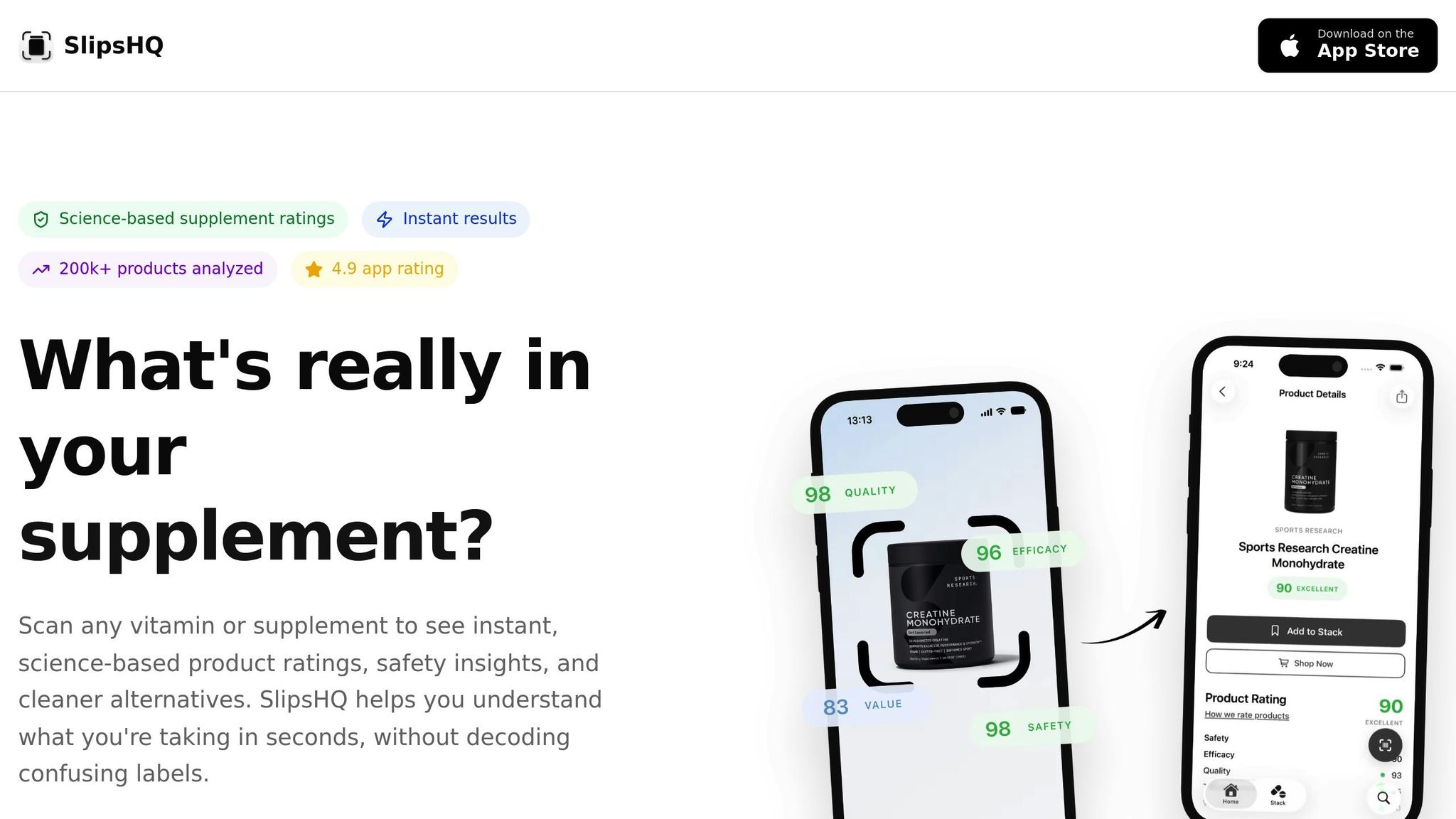
Science-Based Trust Scores
SlipsHQ takes the guesswork out of evaluating supplement research by offering a straightforward 0–100 rating system. This score is based on factors like sample size, study design, and the overall strength of the evidence. The app places a high value on randomized controlled trials with adequate sample sizes - those that use pre-established calculations to achieve about 80% statistical power. Why? Because these features reduce the likelihood of false positives or negatives. For example, if a supplement's main claim relies on a single small trial with unexpectedly strong results, the trust score reflects the higher potential for error and the possibility that these findings might not hold up in future studies.
The system also flags trials that lack sufficient participants to support their claims or fail to include sample size and power calculations. On the flip side, it adjusts for cases where extremely large trials show statistical significance but lack meaningful real-world benefits. This balanced approach ensures that a consistent, modest benefit in a large, well-designed study scores higher than dramatic results from a small, uncontrolled trial.
Barcode Scanning and Personalized Information
SlipsHQ makes it easy to dive into the details of a supplement's claims. By scanning a product's barcode, you can access a summary panel that breaks down key information such as the total number of participants, the number of trials, and the level of evidence supporting each claim. The app categorizes studies into small pilot trials, medium-scale randomized controlled trials, and large-scale investigations. It also checks whether the sample sizes were sufficient to detect the claimed outcomes, based on reported power calculations and effect sizes. Visual badges like "limited early data" or "multiple robust trials" allow you to quickly gauge the reliability of the evidence.
The app goes a step further by evaluating the demographics of study participants. For instance, studies that focus on narrow groups - such as young, healthy males - score lower on generalizability compared to those involving diverse populations. When you scan a product, SlipsHQ highlights whether the key studies are relevant to your own profile, helping you decide how applicable the findings are to your health.
Clear Information and Informed Decisions
SlipsHQ simplifies complex scientific concepts like power, effect size, and confidence intervals with easy-to-understand language and visuals. For example, it might display messages like "Study too small to confirm this effect" or "Study large enough to detect moderate benefits." It also translates effect sizes into practical terms, such as "small, possibly noticeable benefit" or "uncertain effect; results varied widely between participants." For those who want to dig deeper, advanced numerical details are just a tap away.
When small studies show promising results but larger trials do not, SlipsHQ uses a weighted approach to prioritize well-powered, high-quality evidence. This ensures that the trust score leans more heavily on robust research, even if smaller studies seem encouraging. If the evidence is mixed, the app clearly labels it as such and explains why the score might be conservative. This transparency helps you avoid wasting money on supplements that might look effective in large datasets but offer little practical benefit. By focusing on the best available evidence, SlipsHQ empowers you to make smarter, more informed decisions.
Conclusion
Sample size plays a key role in determining whether supplement claims are grounded in solid science or shaky assumptions. Well-designed studies - typically involving at least 50–100 participants for modest effects - are crucial. These studies should report both effect sizes and statistical significance while including diverse populations that mirror real-world users.
When assessing research, look for studies with ≥80% power, group sizes of at least 20–27 participants, and consistent reporting of effect sizes, replication, and adjustments for dropouts. Be cautious of red flags, like dramatic findings from small, underpowered pilot studies.
To make informed decisions, consumers need access to reliable and clearly interpreted research. That’s where SlipsHQ steps in. By analyzing over 200,000 supplements, SlipsHQ simplifies complex study data into an easy-to-understand 0–100 trust score. With a quick barcode scan, you can instantly see whether a product’s claims are supported by studies with adequately sized samples.
Choosing supplements backed by strong evidence ensures you're investing in products that deliver real benefits. Instead of falling for bold claims from poorly designed studies or wasting money on products with statistically significant but clinically irrelevant results, you can rely on SlipsHQ to cut through the noise. With its science-based evaluations, you can confidently build a supplement routine rooted in transparency and credible data - not just marketing hype.
FAQs
Why do larger sample sizes make supplement studies more trustworthy?
When it comes to supplement studies, having a larger sample size makes a big difference. Why? Because it minimizes the influence of random variations and unexpected outliers. With more participants involved, the findings are more likely to reflect how the supplement affects a diverse range of people, providing results that are both reliable and consistent.
On the flip side, smaller studies often struggle with limited data, which can sometimes lead to misleading conclusions. Larger studies, however, paint a much clearer picture of how a supplement might perform across different demographics. So, when you're reviewing supplement research, prioritize studies with a solid number of participants. This ensures the conclusions are backed by strong, dependable data.
Why does sample size matter in supplement studies?
Sample size is a key factor in gauging how reliable the results of a supplement study are. Larger sample sizes increase a study's statistical power, which means they’re better at identifying genuine effects while minimizing the risk of false negatives. On the other hand, studies with smaller sample sizes often face higher variability and a greater chance of random errors, making their findings less dependable.
When reviewing supplement research, focus on studies with a sufficient number of participants and well-structured methodologies. These qualities make the findings more reliable and relevant to a broader audience. To gain a clearer understanding of supplement safety and effectiveness, tools like SlipsHQ can provide data-driven insights to help you make smarter choices.
Why is it risky to base health decisions on small supplement studies?
Small studies on supplements often fall short due to their limited sample size, which can make their results less dependable. With fewer participants, these studies might not accurately reflect the broader population, heightening the chance of skewed or unreliable conclusions regarding a supplement’s safety or effectiveness.
Basing health decisions on such narrow findings could lead to mistakes - like choosing a supplement that hasn’t been properly tested or overlooking one that might actually help. When reviewing supplement research, prioritize studies that involve larger, more diverse participant groups and follow strong research methods. This approach ensures the results are more reliable and relevant to your health needs.